Hows thing are done
My role as a technical architect was focused on guiding the development team, enforcing the governance and adhering to the essence of the solution blueprint. From the face of it, this sounds pretty awesome.I loved being part of the development team and cutting code. I know numbers of architects who are expert Microsoft Visio or Word users. But I prefer the a middle path.
I made choices of the frameworks and patterns that should be used for the solution. I looked at each problem in details, devised solutions and attempted to get the team onboard. I did fail number of times because there were disagreements how things can be done or what framework to use.
It was sometime easier to do the work myself. I would knock off the code within few hours which would have taken a week or so for a developer. In hindsight I think this was a bad decision. I should have tried to get the team onboard but I learned my lesson.
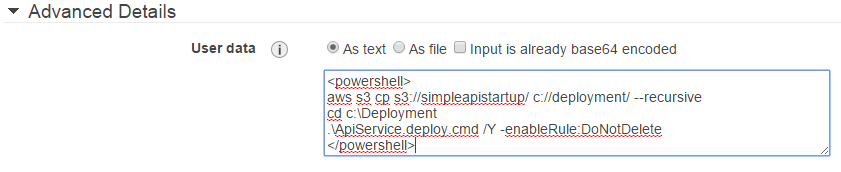
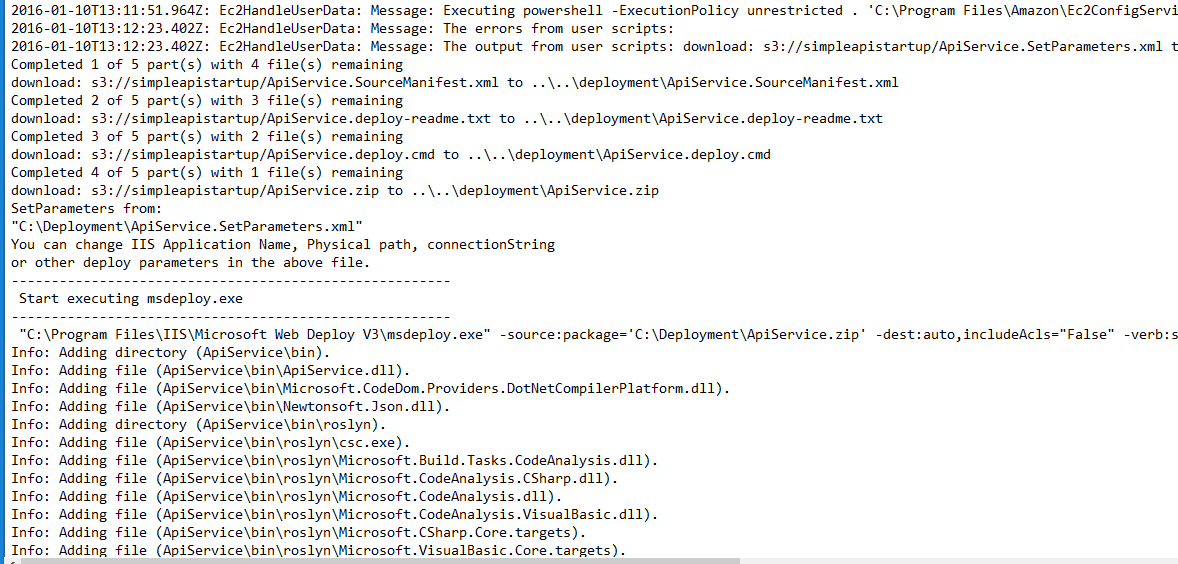
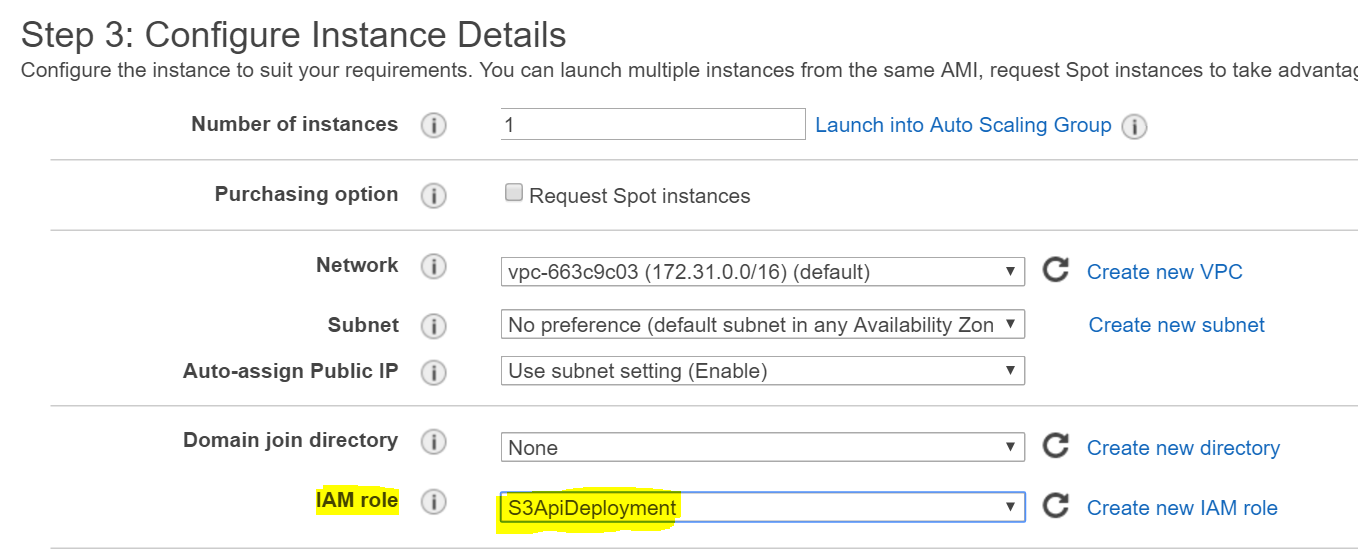
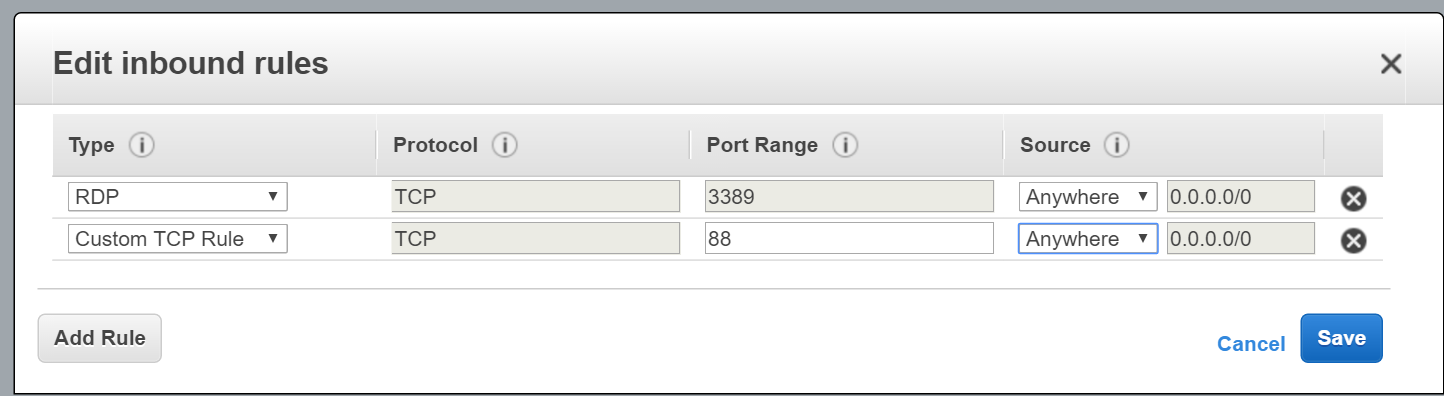
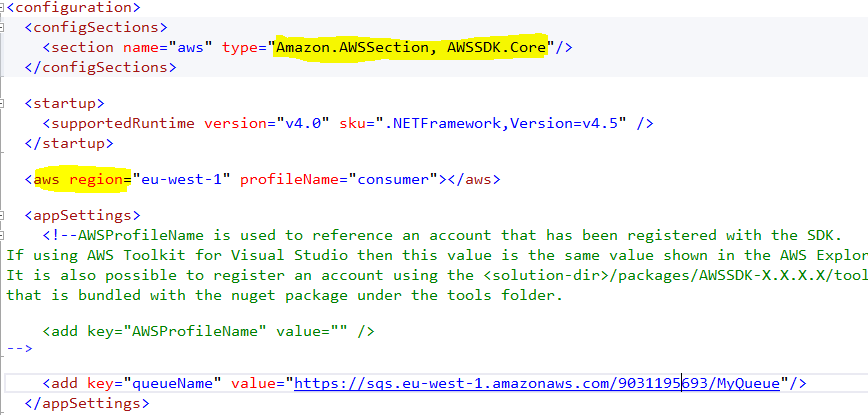
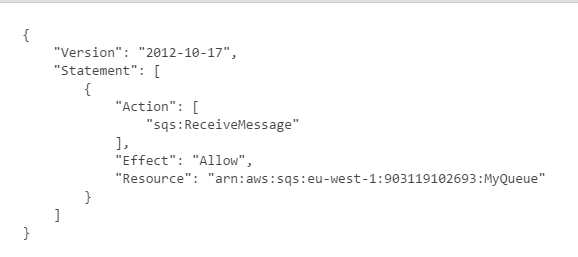
More I spend time with the team, I realised that I was neglecting my duties as a technical architect. I needed put in place deployment, packaging, monitoring and auditing. We used SCOM for some of these, and other alerting mechanisms. I had to talk to other teams and vendors to ensure production environment was ready for the solution.
Lonely
I think leadership of any form force you to a corner. It does not matter you sit with the development team or not. If you are making decisions for a team, you will be isolated.I committed lots of code the solution but no one was there to help with my work. There was no one to talk to Infrastructure team or Networks. I had to carve out time do this. I had to document the design decisions. This took time and I and only I did this.
Even though the developer could shoot off to the pub, I had spend countless hours updating developing documentation and liaising with other teams.
Day T - 1
The day before the release to production is always challenging and nervous. At this point I would have spend countless hours designing, developing and most importantly championing the solution, but nothing prepare you for T - 1.Day T
This is when the solution is available for the public. Great and humble experience!Day T + n
This is the day I received the first production incident.The cycle never stops unfortunately.