Sometime we are so busy "doing stufff" and miss the most basic concepts.
See the following code (LinqPad):
The key factor to consider here whether the code is going to compile. Actually it compiles and executes without any exceptions.
If you look closely you will see "friend.i.Dump()" and "friend.j.Dump()". This might be a cause for concern. This is because "i" and "j" are private members and how come we can call "f.i" in the "Add" method.
The "private" modifier indicates that the members can only be accessed within the same class. So in this particular case we are "inside" the "Friend" class and members are visible. Reference is here.
In order to prevent this confusion, simply use a property. That is simple and universally understood.
Tuesday, 16 December 2014
Wednesday, 12 November 2014
Castle Windsor IoC experiment
I use Castle Windsor for dependency injection at work. The application I work on is a large e-commerce application with many moving parts. I find a DI container such as Castle Windsor (Castle) essential considering the number of dependencies that needs to be resolved.
We use "feature" toggles to control what feature are turned on in Production. I think this is pretty common for any agile organisation. There are times, certain features are not ready and we "turn off" the feature so that the customer do not see it. Again, this is standard practice.
We register the dependencies in Castle using the fluent interface. As new features are developed, the number of dependency installation files increases. Taking a step back from this, I thought if we do not need a feature why its dependencies are registered in Castle in first place. I bet this is not an issue for Castle as there is no request to resolve a dependency. However I believe that if a features is "turned off" then it should not be present in Castle.
So I embarked on an experiment to see how this might work.
There are no surprises here, I simply register types that implement "IAnimal" in the currently assembly. However what I have introduced here is an extension method. The idea is to provide the configuration that determines what dependencies needs to be installed in the container.
I also indicate that the "IAnimal"s that I find should be registered against "IAnimal" in Castle. (If you have used Castle, you know that there is "WithService.AllInterfaces()" that allows you to register types against all the interfaces that a dependency implements.
The extension method is below.
I use the "If" method to register each dependency if it is defined in the "config.Registrations". The key piece of information here is the "registration.UseWith". This defines in what context that the dependency should be used.
An example of an ordinary registration is as follows.
The data structure is pretty standard. It defines the feature key and what is and what is not to be used when a feature is turned on/off respectively.
The full code is in GitHub.
Generally dependencies are registered at "startup". For an web application this means App_Start. This event is triggered at the start of the application and NOT on each request. What I am assuming in the above code is that the application will restart once a feature is turned on or off. I do not think this is the desired behavior. For a large scale application with thousands of users browsing at the same time, service downtime is completely taboo.
So to sum up, I am not convinced that the above solution is going to work for me. It has been a good learning experience going though documentation/Git repo to find out how "stuff" work.
In the next post, I am going to look at the next logical solution "TypedFactories".
Sorry to disappoint. :-(
We use "feature" toggles to control what feature are turned on in Production. I think this is pretty common for any agile organisation. There are times, certain features are not ready and we "turn off" the feature so that the customer do not see it. Again, this is standard practice.
We register the dependencies in Castle using the fluent interface. As new features are developed, the number of dependency installation files increases. Taking a step back from this, I thought if we do not need a feature why its dependencies are registered in Castle in first place. I bet this is not an issue for Castle as there is no request to resolve a dependency. However I believe that if a features is "turned off" then it should not be present in Castle.
So I embarked on an experiment to see how this might work.
Problem description
We have the interface "IAnimal" that has multiple implementation "Bat", "Dog", "Cat" (different features). The idea is to register the correct type based on the feature that is currently enabled.Potential solution
I used the following to register the dependencies in Castle.I also indicate that the "IAnimal"s that I find should be registered against "IAnimal" in Castle. (If you have used Castle, you know that there is "WithService.AllInterfaces()" that allows you to register types against all the interfaces that a dependency implements.
The extension method is below.
I use the "If" method to register each dependency if it is defined in the "config.Registrations". The key piece of information here is the "registration.UseWith". This defines in what context that the dependency should be used.
An example of an ordinary registration is as follows.
The data structure is pretty standard. It defines the feature key and what is and what is not to be used when a feature is turned on/off respectively.
The full code is in GitHub.
Issues and problems
Generally dependencies are registered at "startup". For an web application this means App_Start. This event is triggered at the start of the application and NOT on each request. What I am assuming in the above code is that the application will restart once a feature is turned on or off. I do not think this is the desired behavior. For a large scale application with thousands of users browsing at the same time, service downtime is completely taboo.
So to sum up, I am not convinced that the above solution is going to work for me. It has been a good learning experience going though documentation/Git repo to find out how "stuff" work.
In the next post, I am going to look at the next logical solution "TypedFactories".
Sorry to disappoint. :-(
Tuesday, 7 October 2014
Encapsulation and SOLID (Pluralsight course by Mark Seeman) - My take
The title says it all.
Seriously how difficult it can be to understand Encapsulation. In my mind Encapsulation was simply "information/implementation hiding". If you are one of developers who believe Encapsulation is what I believed, then I strongly suggest following to the this Pluralsight course.
One of the key learning outcomes was understanding Command Query Separation (CQS). We all use this principle in our day to day development. I did not realise the power of this principle until when Mark dissect some confusing code. I learnt why should you make a clear separation between a Command (mutate state) and Query (idempotent). This was really refreshing. Seriously, is it so hard to follow this principle? When you work in a code base that is constantly been modified by half a zone teams cross multiple continent, my answer is Yes.
I have not heard about The Postel's Law (Robustness principle), before this screen cast. If you have, then Good for you!, if not, then you should read NOW!.
We have seen the use (or misuse) of Null for reference types. Have you heard about the Maybe<T> pattern?. This is purely a wrap around the Enumerable<T>. Simply put, if something is being returned then there will be 1 (one) element in the output, and 0 (zero) if none. This is quite useful to avoid returning Null from a reference type contract. I found this slightly confusing first. But once I understood the intent, then I do see the advantages.
So, if you would like to refresh your core OOP skills, then this is the course you should seriously consider.
So, if you would like to refresh your core OOP skills, then this is the course you should seriously consider.
Thursday, 5 June 2014
Do I really need a Hidden field?
As more and more SPA (Single Page Application) comes into life, maintaining state in the client side is critical for user experience.
Traditionally we use the following methods to maintain state in the client side.
I was working on a legacy web application and used a hidden field to maintain state in the client side. During a code review, a fellow developer asked the question "Do we really need a hidden field?".
When the page posts back to the server, all the input elements including hidden fields are sent to the server. So the real question is whether there is a real value by sending this hidden field you used for client-side state management? If your site is getting millions of hits every hour, you would like to keep the traffic between client and the server to a minimum.
Initially this pattern did not register in my brain as I thought it was "odd" to store state as a "class" in the markup. But then again it was not totally insane. However there is the question whether you are bleeding "logic" all-over-the-place.
The most elegant solution might be to use MVVM-type JavaScript library such as KnockoutJs.
It is not an easy task to convince a business to migrate core systems to latest libraries or packages. However as developers (for our sanity) we should attempt to structure code that is modular and easier to maintain!
Traditionally we use the following methods to maintain state in the client side.
- Cookies
- Hidden fields
- Query string
- JavaScript objects
- Local storage
- Session storage
I was working on a legacy web application and used a hidden field to maintain state in the client side. During a code review, a fellow developer asked the question "Do we really need a hidden field?".
Hidden fields
Declaring a hidden field is ever so simple (e.g. <input type="hidden" .../>). Now consider the scenario where the hidden field is defined in a form (e.g. <form> tag). (how we are talking...!).When the page posts back to the server, all the input elements including hidden fields are sent to the server. So the real question is whether there is a real value by sending this hidden field you used for client-side state management? If your site is getting millions of hits every hour, you would like to keep the traffic between client and the server to a minimum.
Set a "class"
My fellow developer suggested to store the state in a "class". Let me explain... Rather than setting a hidden field, add a class to the relevant container (e.g. div) and use JQuery $.hasClass function to check whether the class is set.Initially this pattern did not register in my brain as I thought it was "odd" to store state as a "class" in the markup. But then again it was not totally insane. However there is the question whether you are bleeding "logic" all-over-the-place.
Use modern patterns
I totally understand that none of the above methods are elegant. But remember, few years ago data-binding in JavaScript was unheard of. Even the use of XHR/Ajax was not widespread.The most elegant solution might be to use MVVM-type JavaScript library such as KnockoutJs.
It is not an easy task to convince a business to migrate core systems to latest libraries or packages. However as developers (for our sanity) we should attempt to structure code that is modular and easier to maintain!
Monday, 19 May 2014
Minute with Java Vs C# - Type Covariance
It has been a while since I had a look at Java. (I really have a soft spot for Java!).
There are some really good articles on the web about Type Covariance. In a nutshell this is the ability to preserve/use a specific derived type in place of a general type.
Consider the following Java example. (Compiled with JDK 1.7).
I like the type covariance here. Even tough the "CanDoSomeWork" interface expects "SomeWork", the actual implementation allows a derived type of "SomeWork". In the following context, the type "Cat".
From the consumers point of view, there is no need for casting.
However if you try this in C# you will get the following.
I think what Java compiler has done here is pretty cool, and neat. However I have some doubts.
Normally in a larger/enterprise scale application, IoC containers are used. It is the responsibility of the IoC container to create instances and manage their life-styles. Since the code is normally developed against an abstraction (e.g. interface), the consumer always expects the generalised type (think LSP).
I am not sure how to use this feature really... may be its my lack of imagination or misunderstanding. :-(
There are some really good articles on the web about Type Covariance. In a nutshell this is the ability to preserve/use a specific derived type in place of a general type.
Consider the following Java example. (Compiled with JDK 1.7).
I like the type covariance here. Even tough the "CanDoSomeWork" interface expects "SomeWork", the actual implementation allows a derived type of "SomeWork". In the following context, the type "Cat".
From the consumers point of view, there is no need for casting.
However if you try this in C# you will get the following.
 |
| Type Covariance in C# Vs Java 1.7 (7) |
I think what Java compiler has done here is pretty cool, and neat. However I have some doubts.
Normally in a larger/enterprise scale application, IoC containers are used. It is the responsibility of the IoC container to create instances and manage their life-styles. Since the code is normally developed against an abstraction (e.g. interface), the consumer always expects the generalised type (think LSP).
I am not sure how to use this feature really... may be its my lack of imagination or misunderstanding. :-(
Monday, 12 May 2014
Notes around .NET threading, use of timers etc
I was listening to Jeffrey Richter and he mentioned the how widespread the incorrect use of .NET threads. There is no point reinventing the wheel, simply have a look at the following code. It looks very harmless, however it is a course for real concern.
The comments in the code speak for itself. However is this "better" than using "Thread.Sleep" to pause a thread... :-)
The comments in the code speak for itself. However is this "better" than using "Thread.Sleep" to pause a thread... :-)
Sunday, 12 January 2014
Head First HTML5 - Geolocation notes
- The Geolocation is a pretty much in the HTML5 standard. The goal of Geolocation API is to find out the longitude and latitude of the accessing device (whatever it may be). There are multiple ways of finding the location of the user. These methods are through IP address, GSM triangulation, GPS and WiFi.
- The older browsers may not support Geolocation, therefore we need to ensure that this feature is available before using it.
- The Geolocation API is part of the navigator object. See the following code.
- What is most interesting is the object returned by calling the "getCurrentPosition" position. BTW the "displayPosition" and "displayError" are functions. Basically "getCurrentPosition" takes in 3 arguments. These are success, failure and options. (just search for details.)
- The object returned by "getCurrentPosition" looks like below.
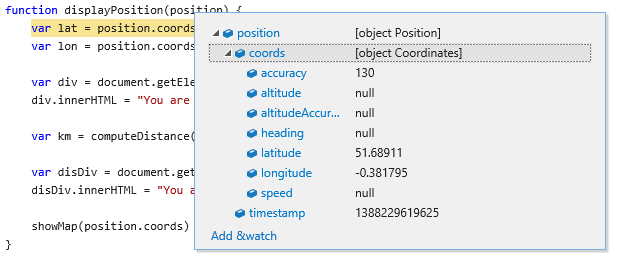 |
| The composition of "Position" object |
- The 3ed argument to the "getCurrentPosition" is the options. The properties that comprise this object are "enableHighAccuracy" (false), "timeout" (Infinity), "maximumAge" (0 - in milliseconds). The browser returns the result that is determined less than the "maximumAge".
- Setting "maximumAge" to 0 may force the browser to get a new position.
- Setting "timeout" to 0 and "maximumAge" to 0 will cause the error handler to be called if there is not a new position immediately. (may call the error handler immediately.)
- Setting "timeout" to 0 and "maximumAge" to 1000 (1 second) may cause the browser to return a position that is less than 1 second old. If not error handler is called.
- The other methods in the Geolocation API are "watchPosition" and "clearWatch". The callback registered in "watchPosition" is invoked whenever the position changes (e.g. moving around). As the "watching" function is expensive we can "cancel" watching by calling "clearWatch". The handler returned from calling "watchPosition" is used to cancel a watch.
Subscribe to:
Posts (Atom)