My attempt is to start a very simple project using ASP.NET MVC WebApi and deploy to AWS. I know there are pre-baked services such as AWS Elastic beanstalk where the deployment is made simple with templates. That is not the point.
I am going to start with poor man's deployment techniques (e.g. copy/paste) and work my way up the AWS platform.
To get started, I need a Windows Virtual Machine in AWS that can be accessed publicly. Then I will deploy my application and access it externally. I am going to deploy a ASP.NET WebAPI project that returns a simple response.
Creating a Virtual Machine
The EC2 Console allows us to launch an instance.
 |
| EC2 Dashboard where the an EC2 instance can be launched |
In order to host the Web API, I am going to select a Windows VM. I have selected a Windows 2012 R2 base image which is AWS free tier eligible.
Public IP address for the instance
 |
| Auto assigning a public IP address to the instance |
Connecting to the Virtual Machine
We can find the public IP address from the EC2 Dashboard. During the launching phase of the VM, I had to create/use key pair (pem file). This is required to decrypt the administrator password.
Once decrypted, I can connect to the VM using Remote Desktop Protocol (RDP).
Deploying the package
I packaged the WebApi solution is packaged as an WebDeploy package, simply to aid in deployment. The packages can simply be copied over to the VM (copy from local machine and paste in VM).
 |
| WebDeploy files copied over to the Windows VM on AWS Platform |
The WebDeploy deployment package can be installed using the generated "cmd" file. I am using "-enableRule:DoNotDelete" flag to prevent WebDeploy from deleting the package.
 |
| Installing the WebDeploy package in Windows VM |
Although the installation was successful, the service cannot be accessed publicly. The firewall of the instance only allows traffic over port 3389 (for RDP). Therefore I need to open the inbound port of the site.
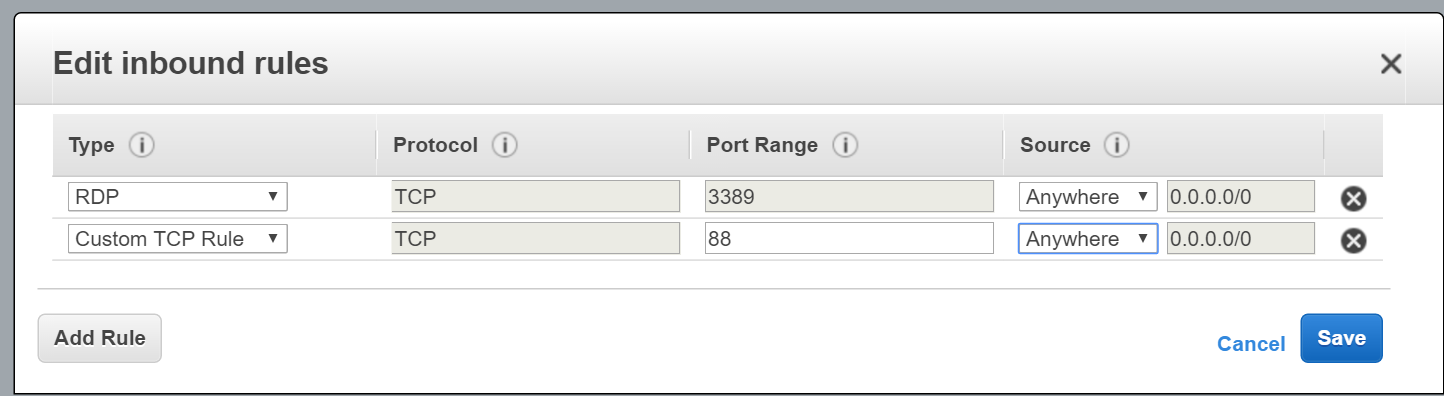 |
| Opening port 88 to the world |
The change to the security group is applied immediately. In addition to this step, I need to open the port through the Windows Firewall because the service is hosted on a non-standard port (I chose to host the site over port 88).
I can now access the service publicly.
 |
| Connecting to the service remotely |
In this task, I simply started up a Windows VM and copied our WebApi code and accessed it over the Internet. Except of for few security group configurations, there was not anything new compared to on-premises deployment.
In the next port I am going to look at how this process can be improved so that we are ready for the "cloud".